 其它资源
其它资源
 友链申请
友链申请
数据库查询优化复盘-20条必备sql优化技巧
0、序言
本文我们来谈谈项目中常用的 20 条 MySQL 优化方法,效率至少提高 3倍!
具体如下:
1、使⽤ EXPLAIN 分析 SQL 语句是否合理
使⽤ EXPLAIN 判断 SQL 语句是否合理使用索引,尽量避免 extra 列出现:Using File Sort、Using Temporary 等。
2、必须被索引
重要SQL必须被索引:update、delete 的 where 条件列、order by、group by、distinct 字段、多表 join 字段。
3、联合索引
对于联合索引来说,如果存在范围查询,比如between、>、<等条件时,会造成后面的索引字段失效。
对于联合索引来说,要遵守最左前缀法则:举列来说索引含有字段 id、name、school,可以直接用 id 字段,也可以 id、name 这样的顺序,但是 name; school 都无法使用这个索引。所以在创建联合索引的时候一定要注意索引字段顺序,常用的查询字段放在最前面。
4、强制索引
必要时可以使用 force index 来强制查询走某个索引: 有的时候MySQL优化器采取它认为合适的索引来检索 SQL 语句,但是可能它所采用的索引并不是我们想要的。这时就可以采用 forceindex 来强制优化器使用我们制定的索引。
5、日期时间类型
对于非标准的日期字段,例如字符串的日期字段,进行分区裁剪查询时会导致无法识辨,依旧走全表扫描。
尽管 TIMESTAMEP 存储空间只需要 datetime 的一半,然而由于类型 TIMESTAMP 存在性能问题,建议你还是尽可能使用类型 DATETIME。(TIMESTAMP 日期存储的上限为 2038-01-19 03:14:07,业务用 TIMESTAMP 存在风险;)
6、禁止使用 SELECT *
SELECT 只获取必要的字段,禁止使用 SELECT *。这样能减少不必要的消耗(CPU、IO、内存、网络带宽),增加使用覆盖索引的可能性;当表结构发生改变时,表结构变更对前端程序基本无影响。
7、避免出现某些字段
SQL 中避免出现 now()、rand()、sysdate()、current_user() 等不确定结果的函数。在语句级复制场景下,引起主从数据不一致;不确定值的函数,产生的 SQL 语句无法使用 QUERY CACHE。
8、where 子句
避免在 where 子句中对字段进行 null 值判断:对于 null 的判断会导致引擎放弃使用索引而进行全表扫描。
避免在where子句中对字段进行表达式操作:因为对字段就行了算术运算,这会造成引擎放弃使用索引。
9、like
禁止使用 % 前导查询,例如:like “%abc”,⽆法利⽤到索引。
在日常中你会发现全模糊匹配的查询,由于 MySQL 的索引是 B+ 树结构,所以当查询条件为全模糊时,例如 %AB%、%AB,索引无法使用,这时需要通过添加其他选择度高的列或者条件作为一种补充,从而加快查询速度。仅AB%形式的可以避免通配符引起索引屏蔽。
10、用 IN 代替 OR
OR 两边的字段中,如果有一个不是索引字段,而其它条件也不是索引字段,会造成该查询不走索引的情况。很多时候都会使用 IN 进行替代,或者使用 union all 或者是 union(必要的时候)的方式来代替“or”也会得到更好的效果。但 SQL 语句中 IN 包含的值不宜过多,应少于 1000 个。过多会使随机 IO 增大,影响性能。
使用 IN 是因为 MySQL 对其做了相应的优化,即将 IN 中的常量全部存储在一个数组里面,而且这个数组是排好序的。但是如果数值较多,产生的消耗比较大。
再例如:
select id from t where num in(1,2,3)
对于连续的数值,能用 between 就不要用 in 了;再或者使用连接来替换。
11、禁止使⽤负向查询
禁止使⽤负向查询,例如:not in、!=、<>、not like。
12、范围查询
在对字符串类型的索引进行大于运算时,会导致全表扫描。所以应改为区间between区间范围运算。
13、order by/group by
另外 order by/group by 的 SQL 涉及排序,尽量在索引中包含排序字段,并让排序字段的排序顺序与索引列中的顺序相同,这样可以避免排序或减少排序次数。如果排序字段没有用到索引,就尽量少排序。
14、禁止使用 order by rand()
order by rand() 会为表增加几个伪列,然后用 rand() 函数为每一行数据计算 rand() 值,最后基于该行排序,这通常都会生成磁盘上的临时表,因此效率非常低。建议先使用 rand() 函数获得随机的主键值,然后通过主键获取数据。
15、尽量用union all代替union
union 和 union all 的差异主要是前者需要将结果集合并后再进行唯一性过滤操作,这就会涉及到排序,增加大量的CPU运算,加大资源消耗及延迟。当然,union all 的前提条件是两个结果集没有重复数据。
16、减少与数据库交互
尽量采用批量 SQL 语句,减少与数据库交互次数。
获取⼤量数据时,建议分批次获取数据,每次获取数据少于 5000 条,结果集应⼩于 1M。
17、复杂查询还是简单查询?
不要用一个SQL解决所有事情,可以分步骤做,省时、易理解、优化。且 MySQL 也十分擅长处理短而简单的 SQL,总体耗时会更短,而且也不会产生臃肿的 SQL,让人难以理解和优化。
拆分复杂 SQL 为多个 小SQL,避免⼤事务。简单的 SQL 容易使用到 MySQL 的 QUERY CACHE;减少锁表时间特别是 MyISAM;可以使用多核 CPU。
18、删除全表数据
delete from table_name;会产生大量 undo 和 redo 日志,执行时间很长,可采用 TRUNCATE TABLE tablename;
19、字符集问题
col_utf8mb4 = col_utf8 关联类型都是 varchar ,但字符集不同,无法使用索引。使用过程中要特别注意。
20、count 优化
这也是一个被面试中经常会问到的问题,对于下面的四条 SELECT 语句:
select count(*) from table … ;
select count(1) from table … ;
select count(primary key) from table … ;
select count(index key) from table …;
哪一条的执行效率最高呢?这个问题需要具体问题具体分析,不能一概而论。这里举 SELECT count(1) 这条 SQL 为例。
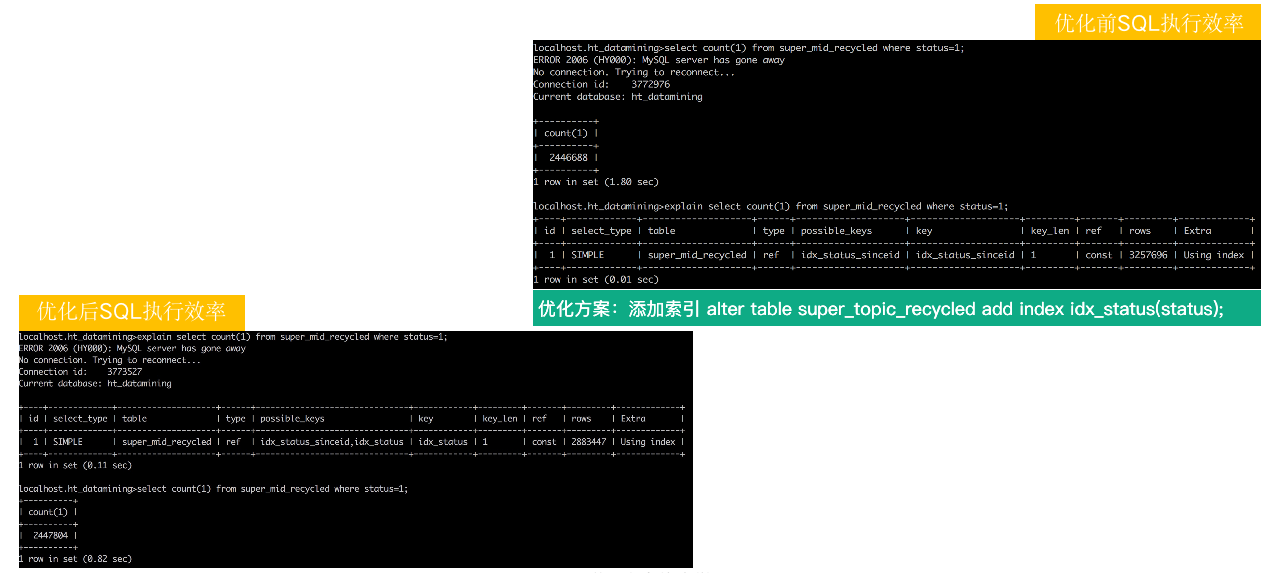
优化前和优化后,执行效率相差2倍。就添加了一个索引。
优化思路 : 是选择索引 key_len 最短的二级索引效率高,不要使用全表扫描(PK 聚族索引会全表扫描),因为索引 key_len 越短,读取页面越少,进而 IO_COST 越小。
小结
- 大量的更新/删除操作需要控制频度,例如:每秒操作2000行以下
- 使用
prepared statement和绑定变量,可以提升性能并避免 SQL 注入 - 程序应有捕获 SQL 异常的处理机制,必要时通过 rollback 显示回滚
- 尽量少使用 distinct、order by、group by、union 等 SQL,排序需求可以放到前端(分页的就不方便交给前端排序)。
- 大事务或者长查询的需求根据业务特点拆分
- 杜绝程序中在处理事务时夹杂 RPC,会造成资源长时间不释放。有很多锁超时、并发数上涨都是由于事务中有 RPC 造成的。
- 关注软件本身的优化同时,也需要关注硬件的性能指标和优化,以及硬件的发展方向。MySQL 属于 IO 密集型的应用,对存储硬件的 IO 性能要求比较高,在高并发的场景中,建议使用 PCI-e。
重点总结一下:SQL 的执行过程->查询优化器的工作原理->SQL 执行计划的解读->MySQL 慢查询日志和分析->SQL 常用的优化手段->SQL 编写规范->深入实际业务对数据库访问进行优化。
参考:
- 《数据库高效优化:架构、规范与SQL技巧》
- 《拉勾教育专栏:高性能MySQL实战》
标题:数据库查询优化复盘-20条必备sql优化技巧
作者:mmzsblog
地址:https://www.mmzsblog.cn/articles/2020/12/01/1606803424583.html
如未加特殊说明,文章均为原创,转载必须注明出处。均采用CC BY-SA 4.0 协议!
本网站发布的内容(图片、视频和文字)以原创、转载和分享网络内容为主,如果涉及侵权请尽快告知,我们将会在第一时间删除。若本站转载文章遗漏了原文链接,请及时告知,我们将做删除处理!文章观点不代表本网站立场,如需处理请联系首页客服。• 网站转载须在文章起始位置标注作者及原文连接,否则保留追究法律责任的权利。
• 公众号转载请联系网站首页的微信号申请白名单!
