 其它资源
其它资源
 友链申请
友链申请
Nginx 为何如此牛逼?

前言
Nginx 的牛逼之处, 想必各位都是有所耳闻, 那么废话我也不多说了, 接下来, 就让我们看看 Nginx 到底是牛逼在什么地方。

论装逼, 我就没输过。
一、Nginx 架构体系
1.1、进程模型
Nginx 采用多进程方式执行,Nginx 启动后,会包含一个 master 进程以及多个 worker 进程。其中 master 进程主要用于管理、监控 worker 进程、接受外部指令以及向 worker 发送指令的功能(这里可以理解为组长与组员的关系,学过 Netty 的小伙伴很容易会理解为 bossGroup 与 workerGroup 的关系,其实都是类似的),而 worker 进程主要是与 client/server 进行连接操作的,进程关系图如下(哦,对了,Redis底层也是类似的结构,感兴趣的小伙伴可以自行查阅):

上图的进程模型yi执行流程可以描述为如下的步骤:
Ⅰ. Nginx 启动后,master 进程监听80号端口,随后 fork 多个 worker 进程。
Ⅱ. 有连接出现时,所有 workers 开始争抢 accept_mutex,只有能抢到互斥锁的 worker 的进程才能 accept 该连接。
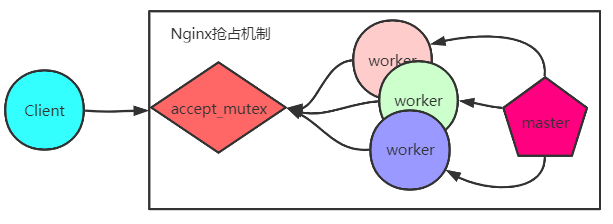
Ⅲ. worker 对接受的请求进行读取,解析,处理,产生响应数据等步骤后,最后断开连接。
总结: 上面的过程就好比是多线程争抢?后,执行 run 方法,这里肯定会有小伙伴✋表示,为啥 Nginx 不直接弄成多线程,非得搞个多进程把问题复杂化。
这里就必须得解释一下:(这也有可能面试会考呦φ(* ̄0 ̄))
⭐由于每个进程是独立的,内部执行不需要加锁,节省了加锁的开销。
⭐某一个 worker 出现问题意外停止,不会影响其他 worker/master。
⭐一个进程只能支持固定的数量的文件描述符(ulimit -n查看,不懂的小伙伴可以看作是支持最大的网络连接数),若需要支持超大量的连接数,开多个进程处理是不可避免的,此处不去纠结单个进程内进行 IO 处理时是否会阻塞,浪费 cpu,单纯只看进程能支持的最大连接数问题。
1.2、Nginx异步非阻塞机制
疑问?
在上面的第3个回答引发思考?:由于 Nginx 一个进程中只有一个主线程,在常规的情况下执行读写操作,必然阻塞,由此也会造成 cpu 浪费的问题。
解释:
Ⅰ. Nginx 采用异步非阻塞的方式处理连接请求,非阻塞?体现在 IO 上,当执行 IO 操作时 cpu 转而去执行其他操作,异步?体现在信号通知上,当 IO 数据从内核空间拷贝到用户空间缓冲区后,利用信号机制通知应用程序 IO 数据已准备?,可以让 cpu 来处理数据了。
Ⅱ. 在 Linux 平台上,Nginx 利用 select/poll/epoll 以及超时时间实现异步非阻塞(select/poll/epoll 一种 IO 多路复用机制,select/poll/epoll 三者功能都是一样的☞可以在单线程下监控多个文件描述符,当某个文件描述符有 IO 请求,通知用户程序去执行 IO 操作,但其在实现方式及性能上存在一定区别,详细内容还请自行百度。下面使用 epoll 举例:在内核空间中,epoll 监控多个文件描述符(监控过程时阻塞状态),当某一文件描述符数据准备就绪(socket 已经连接上),则将数据从内核拷贝到用户空间,随后通知用户进程进行读写操作。一个 epoll 可以监控多个网络连接,宏观下看,单线程也能同时处理多个网络连接)
Ⅲ. 因为 select/poll/epoll 在等待连接的过程时阻塞的,为保证非阻塞,Nginx 利用超时时间实现定时器, epoll_wait 之前从红黑树拿到所有的定时器事件, 判断事件是否超时再执行timeout_handler()或处理网络事件。
二、Nginx 模块解析
2.1、connection模块
? Nginx 作为 web 服务器, 在 master 进程中先初始化 socket, 然后 fork 子进程争抢 accept 事件, 争抢到后, 使用 ngx_connection_t 结构体封装连接, 设置读写函数, 完成与客户端的连接, 连接结束, 释放 ngx_connection_t;
? Nginx 作为客户端, 请求 server (如upstream模块), 过程同上.
? Nginx 使用 worker_connections 设置进程支持的最大连接数(若该值超出系统满足的最大值 Nginx 会给出警告。?最大连接数就是文件描述符数量,可以理解为一个进程能打开最多的文件数 , 使用命令行 ulimit -n 查看?), Nginx 使用连接池管理连接数, 一个 work 进程拥有一个独立连接池(大小为 worker_connections 的 ngx_connection_t 数组), Nginx 所能支持的最大连接数: worker_connections*processes, 在作为反向代理服务器时, Nginx需要两个连接支持客户端与服务端的一个连接,所能支持的最大连接数就得除于2。
疑问?
多个workers竞争accept_mutex时,某一个worker 一直占用 accpet_mute,自己一个人去执行 IO 操作,这就会导致这个worker连接数很快用完, 而其他的 worker 还有很多空余连接, Nginx面对这个问题又是怎么解决的?
解释:
Nginx 内部使用 ngx_accept_disabled 控制 worker 是否竞争 accept_mutex,ngx_accept_disabled 计算方式如下:
当某个 worker 空闲连接数越少则 ngx_accept_disable 越大,其他进程获取到锁的机会越大,反之则越小,靠此机制,Nginx维持了多进程间连接的平衡
//cpp伪代码
ngx_accept_disabled = ngx_cycle->connection_n/8 - ngx_cycle->free_connection_n;
if (ngx_accept_disabled > 0) ngx_accept_disabled--;
else {
if (ngx_trylock_accept_mutex(cycle) == NGX_ERROR) return;
if (ngx_accept_mutex_held) flags |= NGX_POST_EVENTS;
else {
if (timer == NGX_TIMER_INFINITE || timer > ngx_accept_mutex_delay)
timer = ngx_accept_mutex_delay;
}
}
2.2、request模块
? http 请求顺序如下 => 请求行、请求头、请求体、响应行、响应头、响应体。
? Nginx 内部使用 ngx_http_request_t 对 http 请求的封装。
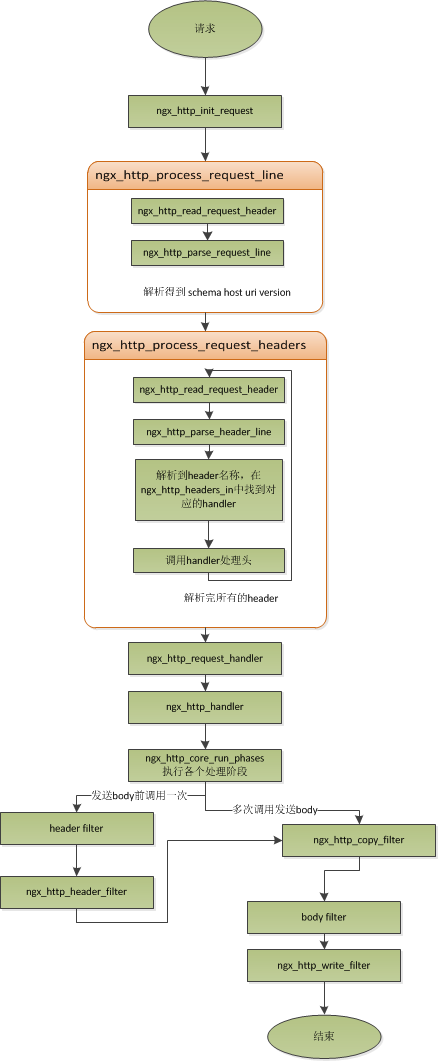
? ngx_hhtp_process_line 处理请求行(在判断httpMethod, Nginx 并没有使用 string 比较, 而使用整型表示, 减少 cpu 指令)
? ngx_http_read_request_header 读取请求头, 解析请求头数据保存在 ngx_http_request_t 的 headers_in 中, 需要特别处理的请求则映射表中获取对应的处理函数(ngx_http_headers_in)
? ngx_http_process_request 处理请求, 设置处理函数 ngx_request_handler , 该函数根据当前事件的读写情况, 分别调用 read_event_handler 或者 write_event_handler 处理。
注: Nginx 的做法是先不读取请求body,而是设置执行函数: 在 ngx_http_handler 函数中, 将 write_event_handler 设置为 ngx_http_core_run_phases;
? 随后执行 ngx_http_core_run_phases , 该函数将 http 请求分为多个阶段进行处理, 执行完处理后, 调用 filter (对数据处理加工, 如压缩), 针对 http 请求来说, filter 有 header filter 和 body filter, header filter 中最后一个 filter 是 ngx_http_header_filter, 该 filter 会遍历所有响应头, 确定哪些响应头需要输出(利用ngx_http_write_filter 输出, 产生响应头放到ngx_http_request_t 的 headers_out 中)
注: Nginx 将整个请求头, 请求行放到 buffer 中( buffer 大小使用client_header_buffer_size 设置), 一个完整的请求头, 请求行只会保存在一个 buffer 中, 若请求头大于 buffer 大小报 400 错误, 若请求行大于 buffer 大小报 414 错误。
总结: 上面描述的 http 请求生命周期,可以用如下的图进行描述:
2.3、keepalive模块
一个连接中可以执行多个请求(所谓的长连接), 在 post 请求下需要提前说明 content-length 表明 body 长度, 未说明报 400;
-
在http1.0协议中:
若响应头中有content-length则可以确定响应body长度, 没有则一直接受数据, 当服务端关闭连接, 表示body接受完成。 -
http1.1协议:
响应消息头中 Transfer-encoding 为 chunked 传输, 则 body 为流式输出, body 被分为多块, 每块的开始有标记记录当前块长度; 在非 chunked 传输, 则情况与 http1.0 一样 -
在 http1.0 默认关闭长连接(请求头 connection 默认值 close ), http1.1 默认 keep-alive ;
Nginx 配置 keepalive_timeout 确定在没有数据传输的情况下, 长连接的存活时间(keepalive_timeout = 0 表示关闭长连接)】】
例: 在网页包含较多图片是, 开启长连接, 可以减少time-wait。
2.4、pipe模块
http1.1 特性, 基于长连接实现, 在 keepalive 下, 用户提交多个请求, 第二个请求必须等到第一个请求处理后才能发起第二个请求, 而 pipe 在第一个请求发送后就能立马发送第二个请求( nginx 对 pipe 的处理是串行的, 内部使用 buffer 缓存, 顺序从 buffer 拿每一个请求数据进行处理), nginx 处理的目的就是减少等待第二个请求头数据的时间
2.5、lingering_close模块
设置延迟关闭时间, 当nginx进行连接close时, 可能还有数据在buffer中, 需等数据从buffer发送出去, 随后再执行关闭操作。
注:参考 Nginx开发从入门到精通
感觉不错还请多多支持一下,爱你哟???ο(=•ω<=)ρ⌒☆
标题:Nginx 为何如此牛逼?
作者:regotto
地址:https://www.mmzsblog.cn/articles/2020/08/06/1596725390137.html
如未加特殊说明,文章均为原创,转载必须注明出处。均采用CC BY-SA 4.0 协议!
本网站发布的内容(图片、视频和文字)以原创、转载和分享网络内容为主,如果涉及侵权请尽快告知,我们将会在第一时间删除。若本站转载文章遗漏了原文链接,请及时告知,我们将做删除处理!文章观点不代表本网站立场,如需处理请联系首页客服。• 网站转载须在文章起始位置标注作者及原文连接,否则保留追究法律责任的权利。
• 公众号转载请联系网站首页的微信号申请白名单!
