 其它资源
其它资源
 友链申请
友链申请
数据库表设计注意事项复盘 置顶!
mysql中如何避免死锁的产生呢?
这里给出一些建议:
- 加锁顺序一致;
- 尽量基于 primary 或 unique key 更新数据。
- 单次操作数据量不宜过多,涉及表尽量少。
- 减少表上索引,减少锁定资源。
- 相关工具:pt-deadlock-logger。
索引命名格式,主要为了区分哪些对象是索引:
- 前缀_表名(或缩写)_字段名(或缩写);
- 主键必须使用前缀“pk_”;
- UNIQUE 约束必须使用前缀“uk_”;
- 普通索引必须使用前缀“idx_”。
InnoDB 表的注意事项
- 主键列,UNSIGNED 整数,使用 auto_increment;禁止手动更新 auto_increment,可以删除。
- 必须添加 comment 注释。
- 必须显示指定的 engine。
- 表必备三字段:id、 xxx_create、 xxx_modified。
- id 为主键,类型为 unsigned bigint 等数字类型;
备份表/临时表等常见表的设计规范
备份表/临时表等常见表的设计规范如下。
- 备份表,表名必须添加 bak 和日期,主要用于系统版本上线时,存储原始数据,上线完成后,必须及时删除。
- 临时表,用于存储中间业务数据,定期优化,及时降低表碎片。
- 日志类表,首先考虑不入库,保存成文件,其次如果入库,明确其生命周期,保留业务需求的数据,定期清理。
- 大字段表,把主键字段和大字段,单独拆分成表,并且保持与主表主键同步,尽量减少大字段的检索和更新。
- 大表,根据业务需求,从垂直和水平两个维度进行拆分。
垂直拆分:
按列关联度。
水平拆分:
- 按照时间、地域、范围等;
- 冷热数据(历史数据归档)。
字段设计要求
- 根据业务场景需求,选择合适的类型,最短的长度;确保字段的宽度足够用,但也不要过宽。所有字段必须为 NOT NULL,空值则指定 default 值,空值难以优化,查询效率低。比如:人的年龄用 unsigned tinyint(范围 0~255,人的寿命不会超过 255 岁);海龟就必须是 smallint,但如果是太阳的年龄,就必须是 int;如果是所有恒星的年龄都加起来,那么就必须使用 bigint。
- 表字段数少而精,尽量不加冗余列。
- 单实例表个数必须控制在 2000 个以内。
- 单表分表个数必须控制在 1024 个以内。
- 单表字段数上限控制在 20~50 个。
禁用 ENUM、SET 类型。
- 兼容性不好,性能差。
解决方案:使用 TINYINT,在 COMMENT 信息中标明被枚举的含义。is_disable TINYINT UNSIGNED DEFAULT '0' COMMENT '0:启用 1:禁用 2:异常’。
禁用列为 NULL。
- MySQL 难以优化 NULL 列;
- NULL 列加索引,需要额外空间;
- 含 NULL 复合索引无效。
解决方案:在列上添加 NOT NULL DEFAULT 缺省值。
禁止 VARBINARY、BLOB 存储图片、文件等。
- 禁止在数据库中存储大文件,例如照片,可以将大文件存储在对象存储系统中,数据库中存储路径。
不建议使用 TEXT/BLOB:
- 处理性能差;
- 行长度变长;
- 全表扫描代价大。
解决方案:拆分成单独的表。
存储字节越小,占用空间越小。尽量选择合适的整型,如下图所示。
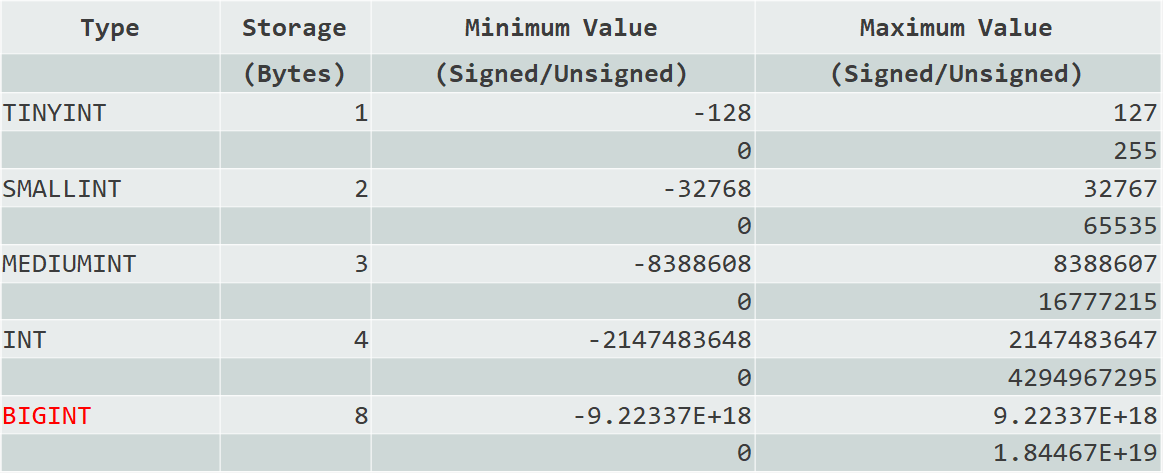
- 主键列,无负数,建议使用 INT UNSIGNED 或者 BIGINT UNSIGNED;预估字段数字取值会超过 42 亿,使用 BIGINT 类型。
- 短数据使用 TINYINT 或 SMALLINT,比如:人类年龄,城市代码。
- 使用 UNSIGNED 存储非负数值,扩大正数的范围。
int(3)/int(5) 区别
int(3)/int(5) 的区别,如下图所示。
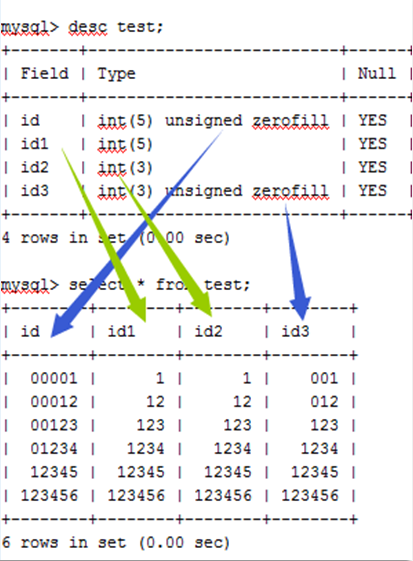
- 正常显示没有区别。
- 3 和 5 仅是最小显示宽度而已。
- 有 zerofill 等扩展属性时则显示有区别。
浮点数与定点数区别
浮点数与定点数区别,如下图所示。
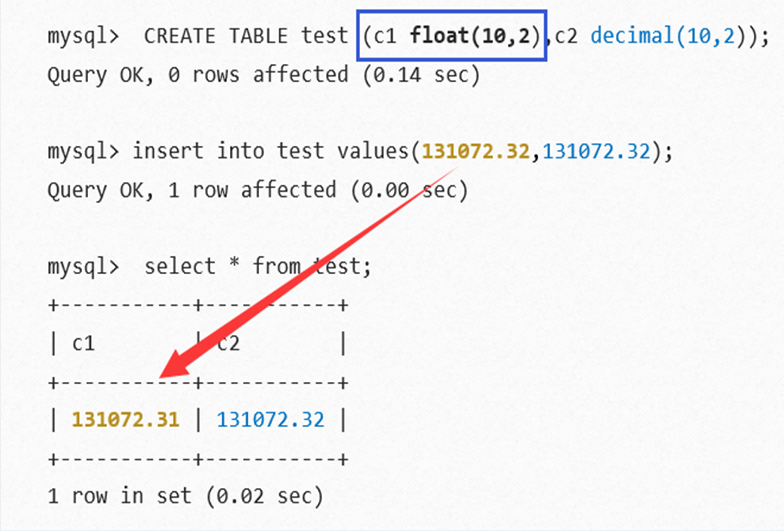
- 浮点数:float、double(或 real)。
- 定点数:decimal(或 numberic)。
从上图中可以观察到:
- 浮点数存在误差问题;
- 尽量避免进行浮点数比较;
- 对货币等对精度敏感的数据,应该使用定点数。
N 解释
字符集都为 UTF8mb4,中文存储占三个字节,而数据或字母,则只占一个字节。
下面看一下字符类型中 N 的解释。
- CHAR(N) 和 VARCHAR(N) 的长度 N,不是字节数,是字符数。
- username 列可以存多少个汉字,占用多少个字节
- username 最多能存储 40 个字符,占用 120 个字节。
IP 处理
一般使用 Char(15) 进行存储,但是当进行查找和统计时,字符类型不是很高效。
MySQL 数据库内置了两个 IP 相关的函数 INET_ATON()、INET_NTOA(),可以实现 IP 地址和整数的项目转换。
因此,我们使用 INT UNSIGNED(占用 4 个字节)存储 IP,非 Char(15)。占 15 个字节。
下图所示,IP:192.168.0.1 与整数之间的转换。
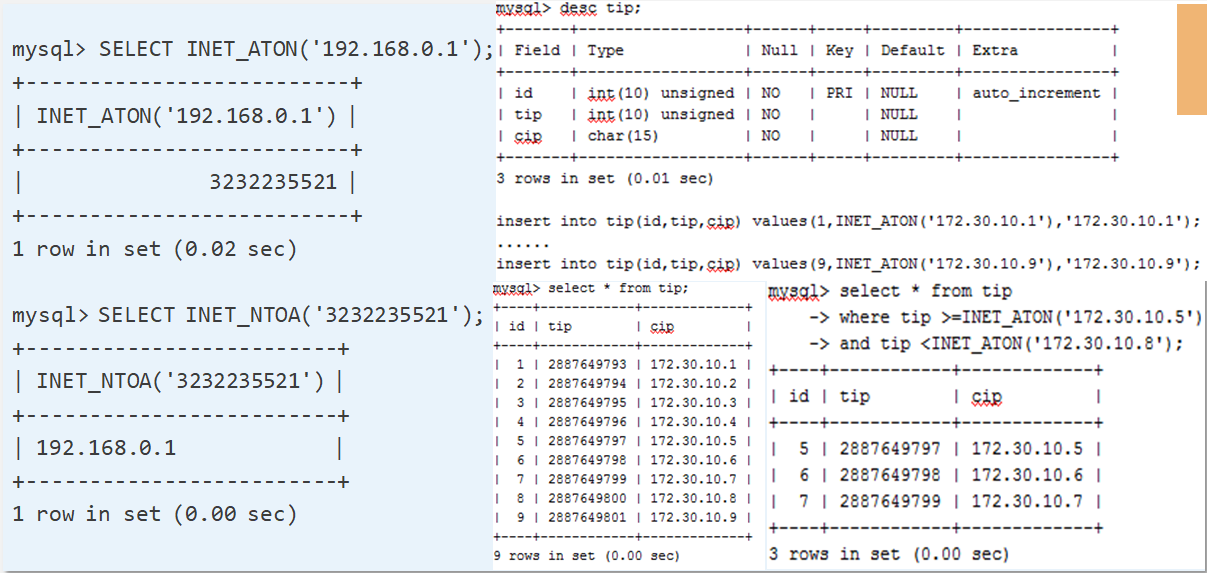
将 IP 的存储从字符型转换成整形,转化后数字是连续的,提高了查询性能,使查询更快,占用空间更小。
TIMESTAMP 处理
同样的方法,我们使用 MySQL 内置的函数(FROM_UNIXTIME(),UNIX_TIMESTAMP()),可以将日期转化为数字,用 INT UNSIGNED 存储日期和时间。
下图示所示,时间 2007-11-30 10:30:19
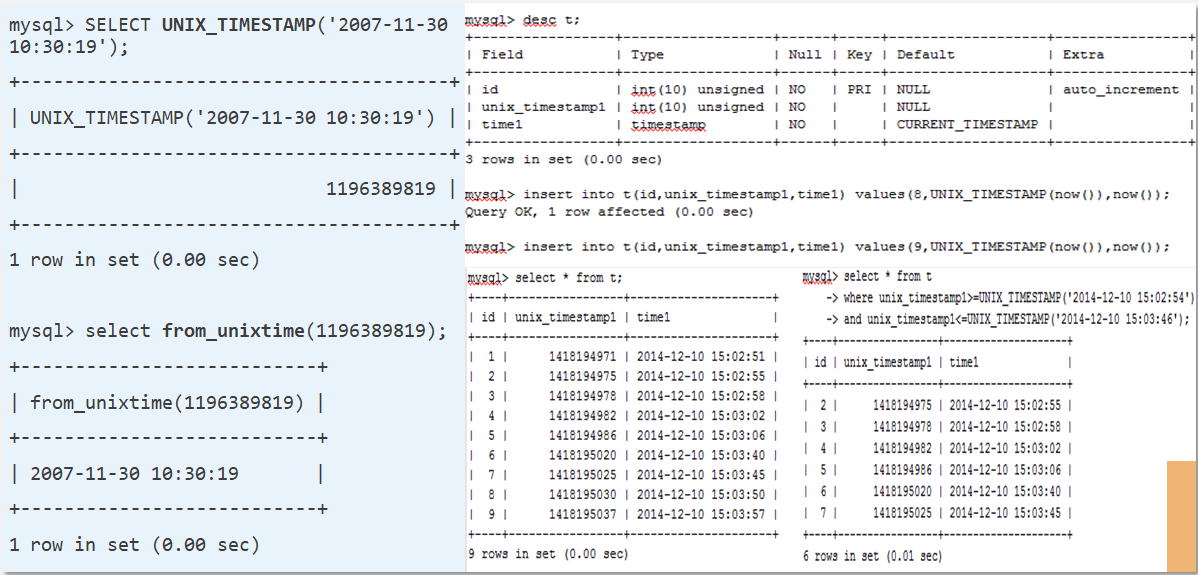
与整数之间的转换,转化后数字是连续的,占用空间更小,并且可以使用索引提升查询性能。
本案例展示的是,不当的数字类型,导致表无法插入新数据,如下图所示。

当我们使用 load data 进行批量加载数据时,会导致 1467 错误。根据分析,导致 1467 错误是由于 auto_increment 的值,超过了 int 类型的取值范围。
原因分析部分显示,max(seq_id) 为 2147477751,而 int 的范围为 -2147483648~ 2147483647,还剩余空间 5896,而程序需要导入 1 万行,所以报错。
解决办法
将 int 改为 bigint 或者将数据分表。
表大小及使用频率
设计表时,必须考虑表的大小和使用频率,避免由于取值范围过小,导致程序运行失败。
对于 InnoDB 表,要求创建一个与业务无关的主键,比如:每张表以 id 列为主键。但是 id 列非常常见,完全无法表达更深层次的意思,特别是在做两张表的联合查询时,它们都有相同的 id 主键的情况下。
如果你的程序用的是列名,该如何区分 Accounts 表的 id 和 Bugs 的 id 呢?如下图所示,列名 id 并不会使查询变得更加清晰。但如果列名叫作 bug_id 或者 account_id,事情就会变得更加简单。
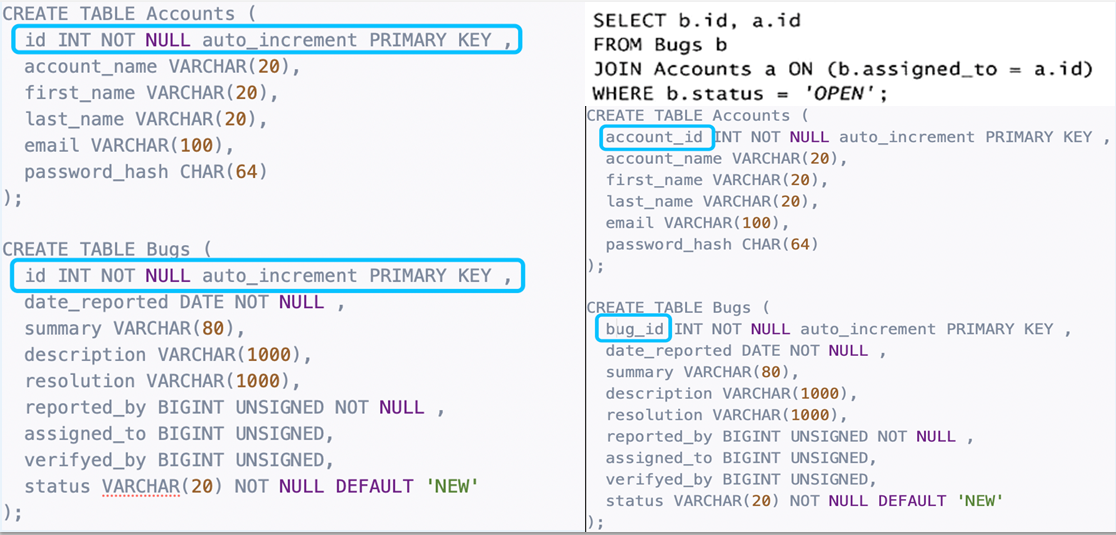
我们使用主键来定位唯一一条记录,因此主键的列名就应该更加便于理解,如下图所示。

- 在缺陷跟踪数据库中,我们使用 Products 表中的 product_id 主键列来关联产品和对应的联系人。每个账号可能对应很多产品,每个产品又引用了一个联系人,因此产品和帐号之间是多对一的关系
- 随着项目日趋成熟,一个产品可能会有多个联系人,除了多对一的关系外,还需要支持产品到账号的一对多的关系。Products 表中的一行数据必须要存储多个联系人。
- 为了把数据库表结构的改动控制在最小范围内,我们决定将 account_id 的类型修改为 Varchar,这样可以在该列中存储多个账号 id,每个账号 id 之间用逗号分隔。
- 这样的设计似乎是可行的,没有创建额外的表和列,仅仅改变了一个字段的数据类型。然而,我们来看看这样的设计所必须承受的性能和数据完整性问题。所有外键都合并在一个单元格内,查询会变成异常困难。只能通过正则表达式进行模糊匹配,不但可能会返回错误的结果,而且无法使用索引提高性能。例如:查询指定产品的账号时,联合两张表将不能使用任何索引。这样的查询必然会对两张表进行全表扫描,并创建一个交叉结果集,然后使用正则表达式遍历每一行联合后的数据进行匹配。
- 出于性能优化方面的考虑,可能在数据库的结果中需要使用反范式的设计。上述 Products 表中将列表存储为以逗号分隔的字符串,就是反范式的一个实例。这个设计只是简化了存储,但是性能低下。因此你需要谨慎使用反范式的数据库设计。尽可能地使用规范化的数据库设计。
- 根据业务需求,我们如何设计合理的反范式,解决方案是:创建一个交叉表。将 account_id 存储在一张单独的表中,而不是存储在 Products 表中,从而确保每个独立的 account 值都可以占据一行。
这张新表 Contacts,实现了 Products 和 Accounts 的多对多关系。当一张表有指向两张表的外键时,称这种表为交叉表,它实现了两张表之间的多对多关系。这意味着每个产品都可以通过交叉表和多个账号关联;同样地,一个账号也可以通过交叉表和多个产品关联。当我们“查询指定产品的账号”时,就可以直接使用下面的联合查询语句高效实现。
总结回顾
本节课主要讲解一些高性能表设计的规则和案例。
以高性能为目标,库表设计以范式为主,根据特殊业务场景使用反范式,允许必要的空间换时间。
规范数据库的使用原则,统一规范命名,减少性能隐患,减少隐式转换。
高性能表设计的原则:合适的字段、合适的长度、NOT NULL。
从不同角度思考 IP、timestamp 的转换,拓宽设计思路。
规范的命名可提高可读性,反范式设计可提高查询性能。
本课时到这里就结束了,主要讲了范式和反范式、基础规范、命名规范、表设计规范、高性能数据库表实践,下一课时将分享“高性能索引如何设计”。
创建索引规范
最后讲解索引创建规范。各个公司都应形成开发规范,MySQL 创建索引规范如下。
- 命名规范, 各个公司内部统一。
- 考虑到索引维护的成本,单张表的索引数量不超过 5 个,单个索引中的字段数不超过 5 个。
- 表必需有主键,推荐使⽤ UNSIGNED 自增列作为主键。 表不设置主键时 InnoDB 会默认设置隐藏的主键列,不便于表定位数据同时也会增大 MySQL 运维成本(例如主从复制效率严重受损、pt 工具无法使用或正确使用)。
- 唯一键由 3 个以下字段组成,并且在字段都是整形时,可使用唯一键作为主键。其他情况下,建议使用自增列或发号器作主键。
- 禁止冗余索引、禁止重复索引,索引维护需要成本,新增索引时优先考虑基于现有索引进行 rebuild,例如 (a,b,c)和 (a,b),后者为冗余索引可以考虑删除。重复索引也是如此,例如索引(a)和索引(a,主键ID) 两者重复,增加运维成本并占用磁盘空间,按需删除冗余索引。
- 联表查询时,JOIN 列的数据类型必须相同,并且要建⽴索引。
- 不在低基数列上建⽴索引,例如“性别”。 在低基数列上创建的索引查询相比全表扫描不一定有性能优势,特别是当存在回表成本时。
- 选择区分度(选择率)大的列建立索引。组合索引中,区分度(选择率)大的字段放在最前面。
- 对过长的 Varchar 段建立索引。建议优先考虑前缀索引,或添加 CRC32 或 MD5 伪列并建⽴索引。
- 合理创建联合索引,(a,b,c) 相当于 (a) 、(a,b) 、(a,b,c)。
- 合理使用覆盖索引减少IO,避免排序。
参考:
- 《数据库高效优化:架构、规范与SQL技巧》
- 《拉勾教育专栏:高性能MySQL实战》
- 《拉勾教育专栏:高并发 MySQL 优化实战》
- 文中图片来源:《拉勾教育专栏:高性能MySQL实战》
标题:数据库表设计注意事项复盘
作者:mmzsblog
地址:https://www.mmzsblog.cn/articles/2020/11/25/1606273152509.html
如未加特殊说明,文章均为原创,转载必须注明出处。均采用CC BY-SA 4.0 协议!
本网站发布的内容(图片、视频和文字)以原创、转载和分享网络内容为主,如果涉及侵权请尽快告知,我们将会在第一时间删除。若本站转载文章遗漏了原文链接,请及时告知,我们将做删除处理!文章观点不代表本网站立场,如需处理请联系首页客服。• 网站转载须在文章起始位置标注作者及原文连接,否则保留追究法律责任的权利。
• 公众号转载请联系网站首页的微信号申请白名单!
