 其它资源
其它资源
 友链申请
友链申请
你竟然说你不懂SQL???
注:本文讲解数据库的基础语法部分以及简单(单表)查询,使用 mysql 数据库进行演示。
mysql登录演示
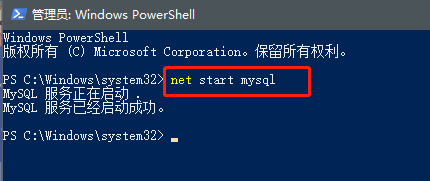
1.启动MySQL服务
==win + x== 启动 Winodws PowerShell(管理员)
输入 " net start mysql " 启动 mysql 服务
2.登录 MySQL
启动MySQL服务后切换到控制台,
==win + R== 调出 "运行", 输入 ==cmd== 启动控制台。
在控制台输入: ==ysql -u root -p==
按下回车键后再键入密码。
看到下图的信息后证明登录成功。

SQL语句演示
1.查看数据库
(注意mysql中所有的语句后面都要带上分号“;”)
语法:==show databases;==

其中的 mysql 、 test 、 information_schema 、 performance_schema 这四个数据库是 mysql 自带来的,不要去动他,我们使用我们自己创建的库来操作。
2.进入数据库
演示使用 gjp 数据库
语法: ==use gjp;==
3.列出数据表
语法: ==show tables;==
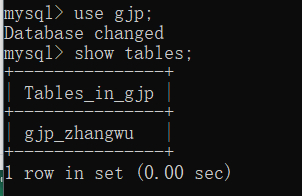
这个数据库中我只有一张表 -- gjp_zhangwu
4.查看表中的所有内容
语法: ==select * from gjp;==
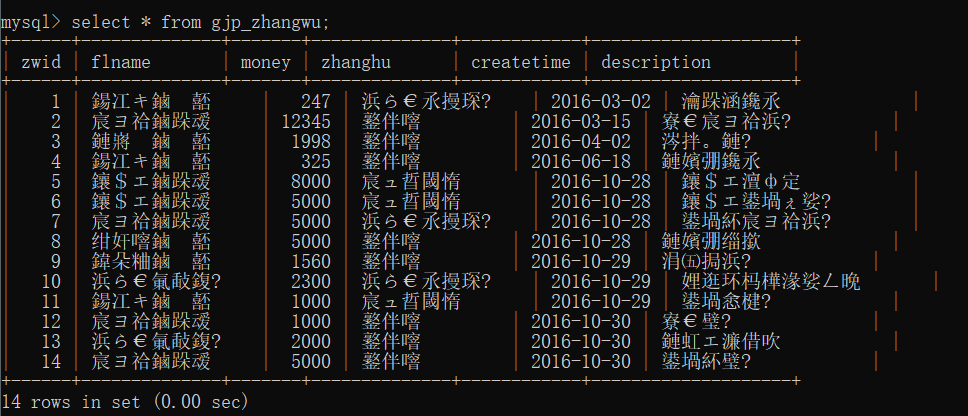
查询后会出现如果所示的乱码问题, 原因是 windows 默认的编码字符集是 GBK ,而 MySQL 配置的时候是以 UTF-8 为默认字符集。出现了字符编码表不统一的问题。
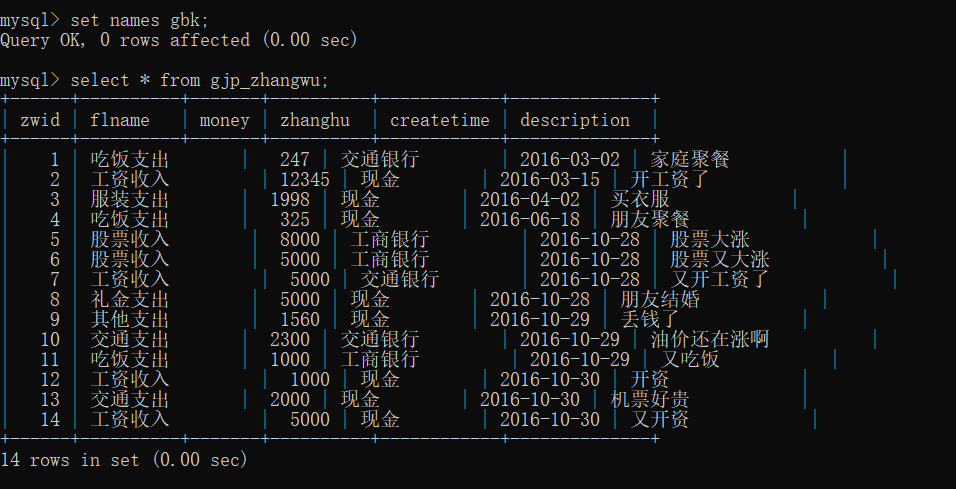
5.更改字符集
语法: ==set names gbk;==
更改完查看的字符集之后重新执行查询语句 select * from gjp_zhangwu;
便会出现一堆我们能够看懂的文字了。
库、表数据修改操作
1.创建库
学习sql的第一步就是要有自己的一个学习数据库啦,所以首先我们要创建一个数据库
语法: create database 表名;
本篇我们以 mydatabase 为名创建一个数据库
create database mydatabase;
如果不小心创建错误了也可以通过
==drop database 库名;==
来将错误创建的库删除掉。
想要排除前文说到的字符编码问题也可以通过
==create database mydatabase character set gbk;==
来创建库,创建的同时就会设置成为 gbk 编码格式。后期我们就不用再去 set names gbk 了
2.创建表
创建完数据库之后要通过 ==use 库名== 来进入数据库
use mydatabase
进入数据库后如果我们 show tables; 会发现这个库中什么都没有。

所以接下来就是创建表的操作了,相比之前的语法稍微会复杂那么一点点,得花一点功夫多敲几遍才能记住。
语法:
create table 表名 {
字段名 类型(长度) [约束],
字段名 类型(长度) [约束],
字段名 类型(长度) [约束]
};
注:SQL中的字符串类型不为 String 而是 varchar(n)
约束在此不过多详细叙述,会根据使用到的约束进行简述,如果想要深入了解 SQL 约束,可以转到 W3C 中查阅
SQL约束
接下来就来创建一张学习使用的表单
CREATE TABLE user(
uid INT(31) PRIMARY KEY AUTO_INCREMENT,
uname VARCHAR(31),
upassword VARCHAR(31)
);
这一段语句,创建了一个有三个字段的表:
第一个字段 uid 类型为 int 长度为 31 ,该字段被标识为主键,也就是在后面增加了一个主键约束(primary key), 后面跟着的 AUTO_INCREMENT 就是自动增长的意思, 该字段会随着表数据的增加
而增加;
第二个字段为 uname 类型为 varchar 长度为 31 ;
第三个字段为 upassword 类型同样为字符串类型 varchar 长度为 31。
3.查看表结构
查看表结构,目的在于我们后面插入数据的时候一旦忘记了表字段的数据类型,就可以先查看一下再来插入数据。
语法:==desc 表名;==

执行 desc 查看表结构,我们就可以清晰的看到 字段名,数据类型,是否为空,是什么键,默认数值,额外约束。后期再进行插入就很方便了。
4.修改表结构
4.1 添加列
语法:==alter table 表名 add 列名 类型(长度) [约束];==
我们来尝试给 user 表插入一个新的信息字段
ALTER TABLE user ADD uinfo VARCHAR(31) NOT NULL;
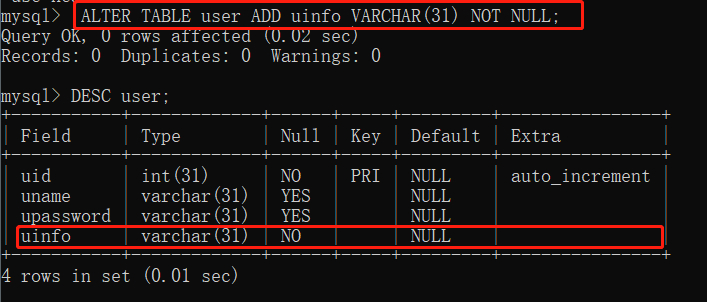
可以看到在添加完新字段后使用 desc 就可以看到我们新增的 uinfo 字段了。
4.2 修改列的类型长度及约束
语法:==alter table 表名 modify 列名 类型(长度) [约束];==
我们来试着将刚刚添加的字段类型长度改长,并将约束设置为可以为空。
ALTER TABLE user MODIFY uinfo VARCHAR(100) NULL;
可以看到修改完之后的 uinfo 字段的 varchar 长度就从 31 变成了 100,约束的非空也被取消了。

4.3 修改列名
语法:==alter table 表名 change 旧列名 新列名 类型(长度) [约束];==
这一次我们来将 uinfo 的字段名改成 info 同时将类型的长度改为 32 并重新设置非空约束。
ALTER TABLE user CHANGE uinfo info varchar(32) NOT NULL;
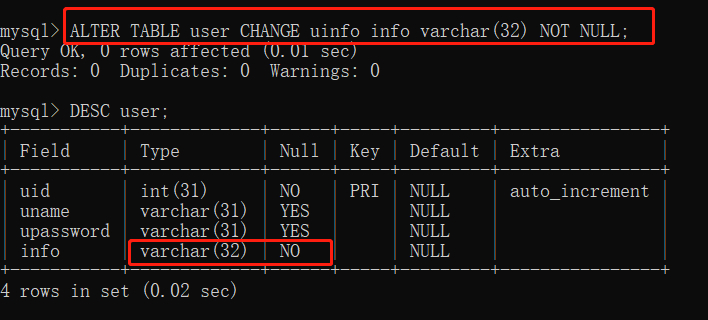
4.4 删除列
语法:==alter table 表名 drop 列名;==
好了,被我们玩坏了的 info 字段暂时失去了他的价值,他是时候退场了。
这时候不要优柔寡断,直接就给他来一个 drop
ALTER TABLE user DROP info;
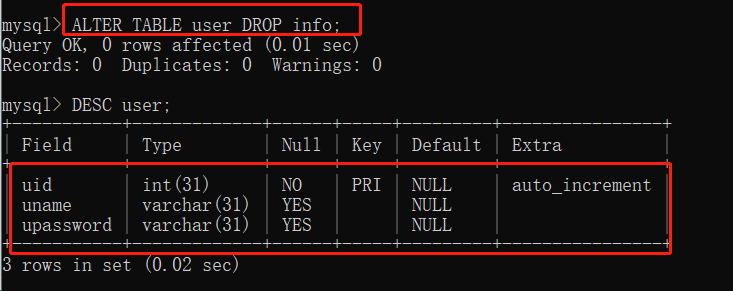
好了,到此为止,info 退出我们的 user 表。
但是记住数据本无价,操作需谨慎。涉及到删除的,最好都是考虑再三后再执行。
4.5 修改表名
语法:==rename table 表名 to 新表名;==
觉得表名不是很心水的话,也可以试着来一个高端一点的名字,比如来个userss。
REANME TABLE user to userss;

4.6 修改表的字符集
我们可以通过查看表的字符集,来查看当前表使用的是何字符集。
语法:==SHOW CREATE TABLE 表名;==
SHOW CREATE TABLE userss;
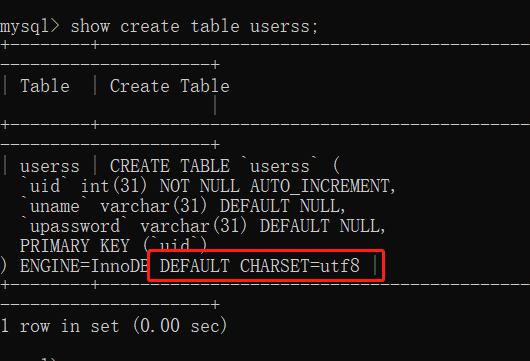
看到了右下角熟悉的 UTF8 了没有,这个就是我们查看的表的默认编码字符集。
而我们的控制台默认是 GBK 编码字符集的,所以我们也能够把表的字符集给换成 GBK,剩得下次查看麻烦。
语法:==alter table 表名 character set 字符集;==
ALTER TABLE userss CHARACTER SET GBK;
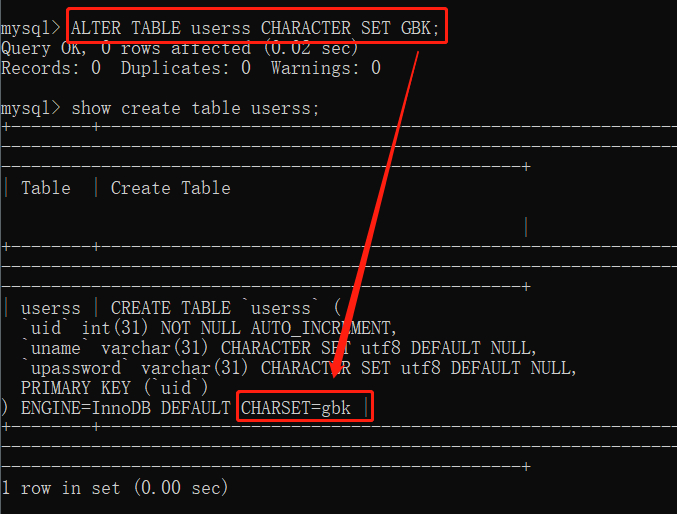
这样就把我们的表从 UTF-8 编码字符集修改成了 GBK 字符集,下次查看此表时就不用再去设置查看的字符集了。
4.6 删除表
语法:==drop table 表名;==
什么?! userss 表你也玩坏了?不想要了?那行吧,也不是没有办法。我们照样可以办他,drop,安排。
DROP TABLE userss;

5.插入数据
讲完了对建库建表,删库删表后就是对表中数据的插入了。这一步就是给数据库灌注营养的一步,让数据库开始有了价值,有了实际作用。
/*插入某些列数据*/
INSERT INTO 表名 (列名1,列名2,列名3...) VALUES (值1,值2,值3...);
/*向表中插入所有列*/
INSERT INTO 表名 VALUES (值1,值2,值3);
注:插入的值和列名个数相等,顺序一致,类型与值要对应,插入值不能大于类型最大长度,sql中的字符串不使用双引号,而使用 ''(单引号)
/*例:
进入mydatabase库 */
USE mydatabase;
/*刚刚的userss表被我们删除了,此时库中是没有表的,所以我们要重新建表*/
CREATE TABLE user (
uid INT(31) PRIMARY KEY AUTO_INCREMENT,
uname VARCHAR(31),
upassword VARCHAR(31)
);
/*使用第一种方法插入数据,带列名的部分插入*/
INSERT INTO user(uname,upassword) VALUES ('zhangsan',123);
/*使用第二种方法插入数据*/
INSERT INTO user VALUES (null,'lisi',456);
我们可以从下图中看到我们使用两种方法插入时都没有写 uid 的数据,但是他居然按照顺序排好了,这就是因为我们给 int 类型的 uid 设置了主键约束,他不能为空,同时也设置了 into_increment 自动增长,所以他就会从 1 开始增长,不需要我们手动去修改。

select 语法是显示表中的数据,暂时不用纠结,稍后我们会对 select 进行详述
6.修改表数据
数据总不是一成不变的,有时候是因为插入错误,有时候是因为数据更新,这时候都要用到数据修改。下面我们就来看看如何修改表的数据。
6.1 不带条件的修改
语法:==update 表名 set 字段名=值, 字段名=值, 字段名=值……==、
这种方法使用于要将所有的表数据都修改的情况,一旦成功执行操作,所有的记录都会被修改。
/*将表中的password字段全部修改成 666 */
/*注意 password 的类型是 vaechar 所以要用单引号*/
update user set upassword='666';
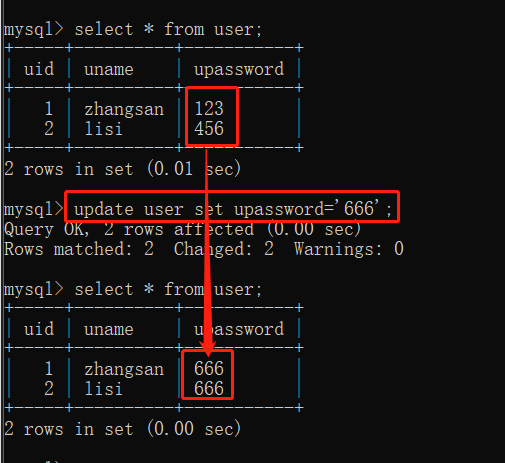
执行完该语句后可以发现,所有的 password 都变成了 666。
6.2带条件的修改
语法:==update 表名 set字段名=值, 字段名=值, 字段名=值…… where 条件==
使用这个修改方式,可以修改部分我们想要修改的字段,其实也很简单,就是在后面加一个 where 关键字再跟上我们的条件。
/*将 zhangsan 的密码重新改回 123*/
UPDATE user SET upassword='123' WHERE uname='zhangsan';
/*where 后面也可以使用 zhangsan 的 uid */
/* UPDATE user SET upassword=‘123’ WHERE uid=1;*/

这一次不同于前面的方法,只有符合 where 后面的条件的数据才会被修改。
7.删除表数据
7.1带条件的删除
语法:==delete from 表名 where 条件;==
/*将表中 zhangsan 的数据删除掉*/
DELETE FROM user WHERE uname='zhangsan';

执行完之后表中的 zhangsan 一行的数据也就不见了,只剩下 lisi 。
7.2不带条件的删除
语法:==delete from 表名;==
为了演示清晰,我们先来插入两个新的数据,以便于更好的观察到不带条件的删除是什么样的。
/*数据准备*/
INSERT INTO user VALUES (null,'zhangsan','123');
INSERT INTO user VALUES (null,'wangwu','789');

我们给表格重新插入了两个数据,现在我们的表中就有了三个数据。
值得注意的是:
自动增长的 uid 行不会从 1 重新开始排列,这是以为数据库还存有一个备份映像,以供操作失误时可以恢复。
现在来演示一下不带条件的删除。
DELETE FROM user;

原本存在三条数据的 user 表,执行了不带条件的删除后,重新查询该表,就只剩下了 Empty 空表了。
不带条件的删除和修改都是对表的整体删除。这也是我为什么多加几条数据进去的原因。
8. delete与truncate的删除区别
在 SQL 的删除操做中,还有另外的一种删除方式,关键字为 truncate 。
在上面的操作中,我们能够看到 uid 在我们 delete 之后并不会复位,而是一直按照顺序走下去,不会因为我们删除了 uid 为 1 的数据后重新插入而变为 1。
这是因为 delete 的删除方式是从表中一条一条的删除,它可以配合事务进行回滚,复原被删除的表的数据。
而如果我们使用 truncate 进行删除,则 uid 会直接复原。因为 truncate 的删除方式是将整张表摧毁,然后生成一张新的表,再将原来的表删除后剩下的内容重新填充进去。这就是使得 truncate 删除后的 uid 能够重新复位的原因。但是因为这种删除的方法,使得 truncate 删除后的表无法复原。
数据查询操作
数据准备:为了更好的演示数据的查询,我们需要事先准备好一张有较多数据的表。
下面我直接给出建表的代码:
USE DATABASE;
set names gbk;
CREATE TABLE product(
pid INT PRIMARY KEY AUTO_INCREMENT,
pname VARCHAR(20),
price DOUBLE,
pdate TIMESTAMP
);
INSERT INTO product VALUES (NULL,'冬瓜',15,NULL);
INSERT INTO product VALUES (NULL,'西瓜',38,NULL);
INSERT INTO product VALUES (NULL,'南瓜',-355,NULL);
INSERT INTO product VALUES (NULL,'白菜',50,NULL);
INSERT INTO product VALUES (NULL,'卷心菜',70,NULL);
INSERT INTO product VALUES (NULL,'空心菜',1,NULL);
INSERT INTO product VALUES (NULL,'酸菜',698,NULL);
1. 简单查询
现在是时候揭晓 SELECT 的神秘面纱了。 他是查询的关键字,我们在表中要找出我们想要的信息,都是通过 select 来实现的。
1.1查询所有商品
首先我们来讲讲最简单的查询 也就是在前面我们见到的 select * from user;
不用我说你也看得出这个 user 是一个表名吧。
查询所有信息语法: ==SELECT * FROM 表名;==
这里的 ‘*’表示的意思就是,全部列,查询出表中所有的列的信息,即将 pid,pname,price,pdate 全部都列出来的意思。
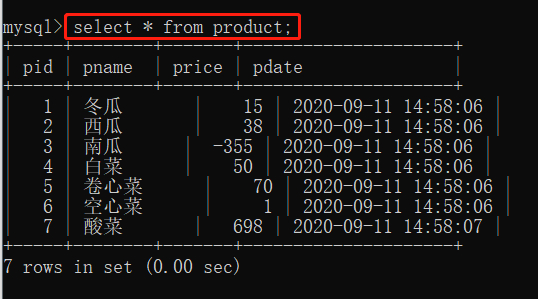
1.2 查询部分信息
有时候我们不想要查询出所有的信息,而只想要看到自己想要的信息。我们可以将 ‘*’ 改成我们想要的列名即可。
下面我们来查看一下商品名和商品价格。
语法:==SELECT panme,price FROM product;==
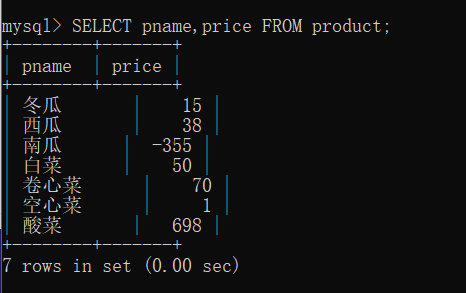
查询的结果就只是我们在 select 后面写的那两行显示出来,这样做有一个好处就是我们看起来方便,在数据很多的情况下,也不会显得过于混乱难以阅读。
1.3 查询部分信息并采用别名
在查询的时候列名不是一直要按照表中原来的名称来显示的,如果你想要给查询出来的列名换一个名字,也不是没有办法,只需要一个 AS 即可。
我们来重新对商品名称和商品价格执行查询,这一次我们要把查询出来的列名换成中文的。
语法:==SELECT pname AS 商品名称,price AS 商品价格 FROM product;==

我们可以看到,pname 的列和 price 的列都被换成了 AS 后面对应的名称,我们将这种做法称为取别名,就是用别名来替换列原来的名字,但是不会影响列本身在表中的名字。
就像我有一个小名,有时候别人喊我的这个小名就知道是在喊我,但是我本身的名字还是那个名字,身份证上的名字可不会育因为我有了一个小名而变了。
1.4去掉重复值
表中的数据永远没有定数,我们也没有给全部的列都加上一个唯一约束,限制所有的值都不重复也不合理。
我们在查询的时候也会出现很多不一样的需求,有可能会因为过多的重复的值导致我们阅读压力很大。我们也能够通过 sql 语法来解决这种问题。
数据准备:
INSERT INTO product VALUES (NULL,'空心菜',1,NULL);
我们来插入一段重复的数据,用来演示我们要做的去掉重复值查询。
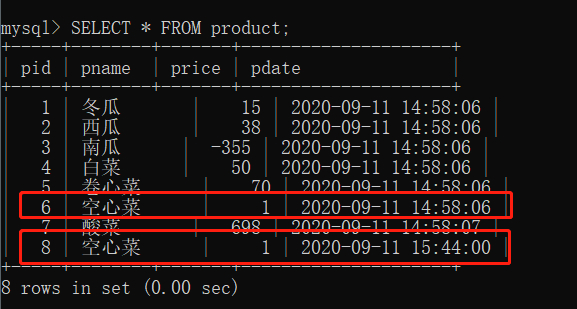
插入后,表中此时有两个相同的值,空心菜。
我们来对价格这一列做一个去重查询。
语法:==SELECT distinct(列名1) FROM 表名;==
SELECT distinct(price) FROM product;

查询结果中,我们本应该出现两个 1 的,因为我们表中有两个空心菜的重复值,distinct 就是去掉重复的值后显示。不过你大可放心,这个效果只作用在查询结果,并不会影响你表中原来的数据。
所有的查询都只是对结果的不同表现形式,不会影响我们表中的数据。
1.5 对表中的数据进行运算后输出
假设我们因为活动的原因,所有的菜价都便宜了 10 块钱,这时候我们不用对原来的菜价进行更换,只需要在查询的时候加上我们要修改的值即可。等活动过去了,我们的菜价还是正常的,我们就不用再费大力气去重新改回来。
语法: ==SELECT pname,price-10 FROM product;==
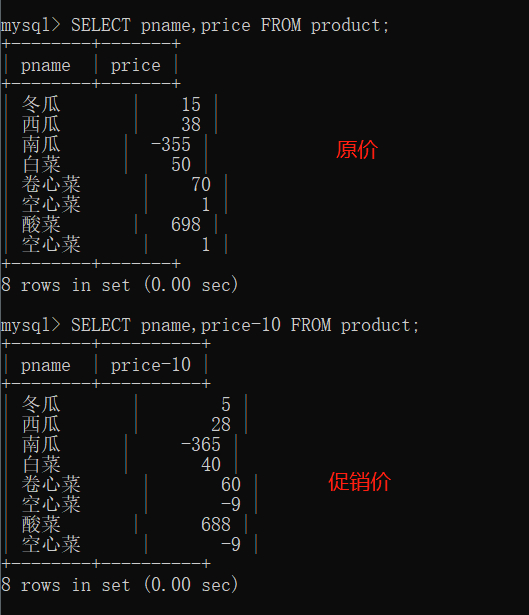
上面的表是按照原来的价格显示的,下面的表是进行运算后显示的。当然,真实情况不会出现负值的价格。这只是对表初始数据的准备问题。
我们只关注数据的运算结果。
2. 条件查询
查询因为条件查询功能的存在而变得威力巨大。
2.1 按照商品名称符合的条件进行查询。
如果我们想要找出某个商品的信息,或者是相查看某个商品是否存在,我们就可以通过条件来控制。
我们来找出名为“空心菜”的商品信息。
语法:==select * from product where pname='空心菜';==
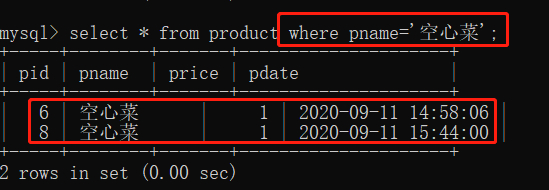
我们表中一开始就存在的 空心菜的信息,以及我们刚刚为了演示去重查询而添加的空心菜的信息全都被查询出来了。
条件查询的作用就是将所有符合条件的查询都罗列出来。
2.2 按照商品价格符合区间查询
sql 远不止只能使用 = 这么低级,我们也可以通过对数据的区间进行查询。
我们来找出价格大于 50 的商品
语法:==SELECT * FROM product WHERE price > 50;==

我在下面查询显示了表的全部内容,用来跟上面的价格区间查询做一个比较,这样能够很清晰的看到,只有价格大于 50 的卷心菜和酸菜的信息被显示了出来。
2.3 模糊查询
在 SQL 中,有通配符的存在,使我们能够对不是非常具体的条件进行查询。
| 通配符 | 含义 |
|---|---|
| % | 任意多个字符(包括0个) |
| _ | 任意一个字符 |
| [] | 指定范围内的单个字符,如[e~h]表示e、f、g、h中任意一个字符 |
| [^] | 不在指定范围内的单个字符,如[^e~h]表示e、f、g、h外的任意一个字符 |
我们的商品表中有瓜,有菜,我们来查询出表中所有的瓜的信息。
SELECT * FROM product WHERE pname like '%瓜';
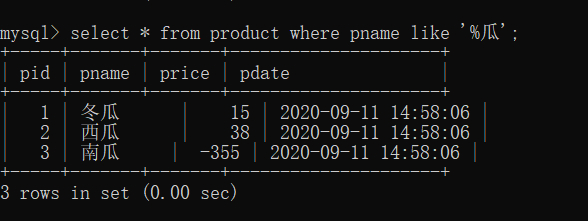
like即为像的意思,
从表中得知,%就是表示任意多个的字符,所以这个条件就是最后一个字符是瓜就行。
我们再来查询商品名称含有“心”的信息。
SELECT * FROM product WHERE panme like '%心%';
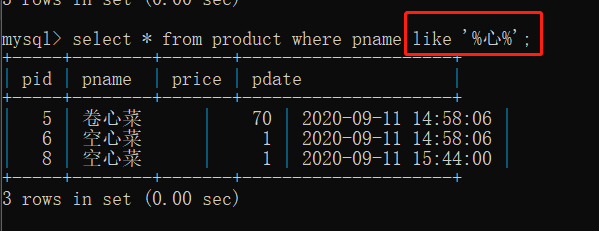
通配符的使用可没有要求说只能用一个哦。
2.4 使用in and or进行区间查询
除了使用符号表示区间外,还有另一种区间查询的方式就是使用 in,and,or。
and 就是“和”的意思,表示要 and 的的条件同时成立才能够显示;
in 和“=”的意思相似,表示值与 in 的条件相同时即可;
or 就是“或者”的意思,表示 or 两边的条件只要有成立的即可。
/*查询商品id 为3,6,9的商品信息*/
SELECT * FROM product WHERE pid IN(3,6,9);

因为我们的表中只有 8 条数据,不存在 id 为 9 的商品,所以就显示了两条信息。
/*查询 pid 为 2 的瓜的商品信息*/
SELECT * FROM product WHERE pid=2 AND pname like '%瓜%';

/*查询商品 id 为 2 或 6的商品*/
SELECT * FROM product WHERE pid=2 OR pid=6;

3. 排序
查询的结果只是按照表中的顺序来显示,但是我们也能够让他们按照我们想要的顺序来排列。
如果我们关心的是价格的排序,我们就可以通过查询的结果按照价格来进行升序、降序排列。
/*查询所有商品,按照价格升序排列*/
SELECT * FROM product ORDER BY price asc;
/*查询所有商品,按照价格降序排列*/
SELECT * FROM product ORDER BY price desc;

升降序的差别只在最后一个关键字,asc 是控制升序,desc 是控制降序。
ORDER BY 关键字用于对结果集按照一个列或者多个列进行排序。
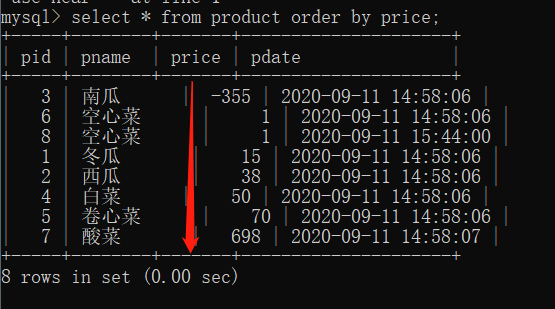
ORDER BY 关键字默认按照升序对记录进行排序。所以我们可以选择不给order by添加一个asc,如果想要降序排列再添加 desc 即可。
/*查询名称有"心"的商品信息并且按照价格降序排序*/
SELECT * FROM product WHERE pname LIKE '%心%' ORDER BY price desc;
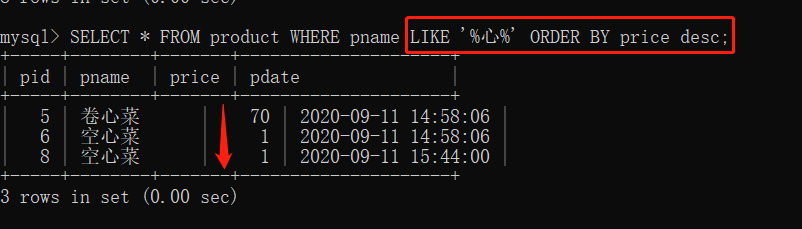
4. 聚合函数
SQL 提供了一些库函数供调用,他们就是接下来准备出场的聚合函数。
最为常见的聚合函数有 求和、求数量、求平均数等。
让我们通过对表的操作来了解。
/*获得所有商品的价格的总和*/
/*将价格作为参数传入SUM函数中,用AS给查询结果列取一个别名*/
SELECT SUM(price) AS 总价格 FROM product;

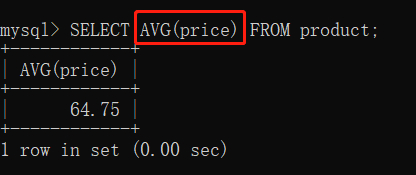
/*获得所有商品的平均价格*/
SELECT AVG(price) FROM product;
/*获得所有商品的个数*/
SELECT COUNT(*) FROM product;

5. 分组
表中的数据如果存在一些没有表名的属性相同,我们要对他们进行归类,sql 还有一个技术叫做分组。
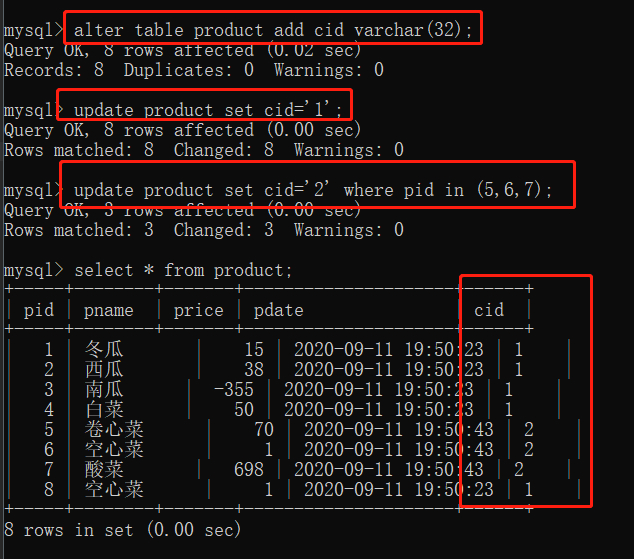
分组首先我们要对表中的数据添加一个分组依据,我们暂且命名为 cid ,也就是给我们的 product 表添加一个 cid 列。
/*添加一个 cid 列*/
ALTER TABLE product ADD cid VARCHAR(32);
对 cid 列初始化数据:
/*将 cid 所有的值都初始化为 1 */
UPADATE product SET cid='1';
/*再将 pid 为 5,6,7 的这三商品分成一组*/
UPADATE product SET cid='2' WHERE pid IN (5,6,7);
添加完 cid 列并分组后的结果
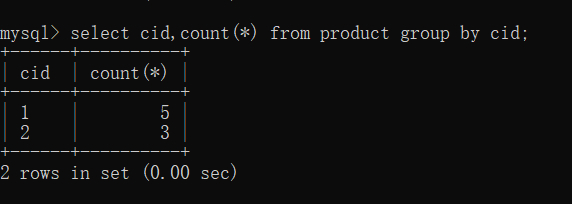
接下来来对分组后的数据进行操作:
/*根据cid字段分组,分组后统计商品的个数*/
select cid,count(*) from product group by cid;
我们可以从查询结果中看到,cid 为 1 的一组总共有 5 个。 cid 为 2 的总共有 3 个,正好和查询结果相对应,这也就是分组的作用。
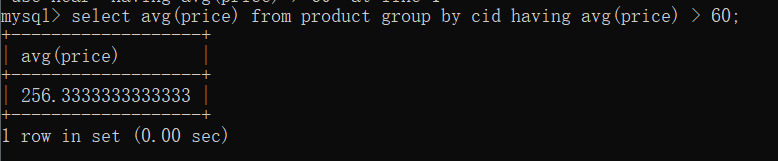
分组也可以和聚合函数产生另外的妙用,比如
根据cid分组,分组统计每组商品的平均价格,并且平均价格大于60元。
select avg(price) from product group by cid having avg(price) > 60;
6. 总结
| 关键字 | 注意事项 |
|---|---|
| select | 一般在的后面的内容都是要查询的字段 |
| from | 要查询的表 |
| where | |
| group by | |
| having | 分组后带有条件只能使用having |
| order by | 它必须放到最后面 |
标题:你竟然说你不懂SQL???
作者:spirit223
地址:https://www.mmzsblog.cn/articles/2020/09/11/1599826440586.html
如未加特殊说明,文章均为原创,转载必须注明出处。均采用CC BY-SA 4.0 协议!
本网站发布的内容(图片、视频和文字)以原创、转载和分享网络内容为主,如果涉及侵权请尽快告知,我们将会在第一时间删除。若本站转载文章遗漏了原文链接,请及时告知,我们将做删除处理!文章观点不代表本网站立场,如需处理请联系首页客服。• 网站转载须在文章起始位置标注作者及原文连接,否则保留追究法律责任的权利。
• 公众号转载请联系网站首页的微信号申请白名单!
